Block AIs from reading your text with invisible Unicode characters while preserving meaning for humans.
Detailed Explanation
LLMs (Large Language Models) like ChatGPT don't actually read text like we do. They only understand words translated into lists of numbers called "tokens." Every word in the English language can be split up into these tokens, and each token is associated with the meaning of that word (or the parts of the word) in the model's training. However, invisible Unicode characters like the ones Gibberifier uses aren't used in real text often enough to warrant their own tokens, so the tokenizer (the algorithm that turns words into tokens) just represents them as the raw UTF-8 byte data that they are stored as in computers. (something like "U+FE12")
When you gibberify text, the AI doesn't see "Hello" - it sees something like "H[U+FE12][U+FEB2][U+FE82]e[U+FB12][U+FE18][U+FE12]l[U+FE18][U+FE12][U+FB12]..." The model receives a bunch of seemingly random byte tokens that are too long for its "context window" (the amount of text it can read in one go, which is normally too high to worry about) and break the tokenizer's ability to join whole words together into tokens. Imagine if you could only read one letter at a time but have to sort through a bunch of meaningless numbers.
Still curious? Check out OpenAI's Tokenizer Demo or talk to Will Patti.
How to use: This tool works best when gibberifying the most important parts of an essay prompt, up to about 500 characters. This makes it harder for the AI to detect while still functioning well in Google Docs. Some AI models will crash or fail to process the gibberified text, while others will respond with confusion or simply ignore everything inside the gibberified text.
Use cases: Anti-plagiarism, text obfuscation for LLM scrapers, or just for fun!
Even just one sentence's worth of gibberified text (at a high intensity) is enough to block almost all LLMs from responding coherently.
Tested Against AI Models
 ChatGPT
ChatGPT
Result: Doesn't understand gibberified text - either hits context limits or realizes that something is wrong but that it can't do anything about it.
See ChatGPT → Gemini
Gemini
Result: Gemini can't process the invisible characters and sometimes has a stroke.
See Gemini → Grok
Grok
Result: Says something "funny" like "sometimes less is more" as a response to its context limit being reached.
See Grok →🕷️ Breaks Web Scrapers Too
Gibberified text also breaks AI-powered web scraping tools
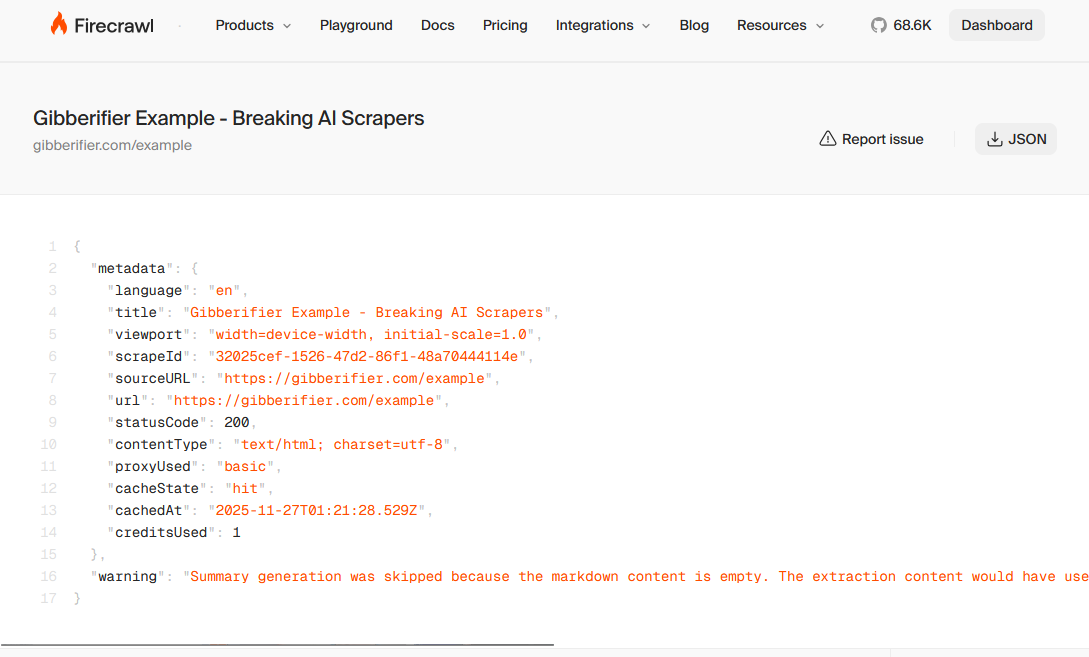
🔥 Firecrawl
Result: Firecrawl's AI scraper fails to extract any content from gibberified text.
📄 TLDR This
Result: TLDR This summarization tool cannot process gibberified content properly.

